子曰:学好正则,走遍天下都不怕
1.RegExp 对象
JavaScript 有两种方式表示RegExp 对象:
- 字面量
- RegExp 构造函数
字面量
1 | const reg = /all/ |
RegExp 构造函数
1 | const reg = new RegExp('all') |
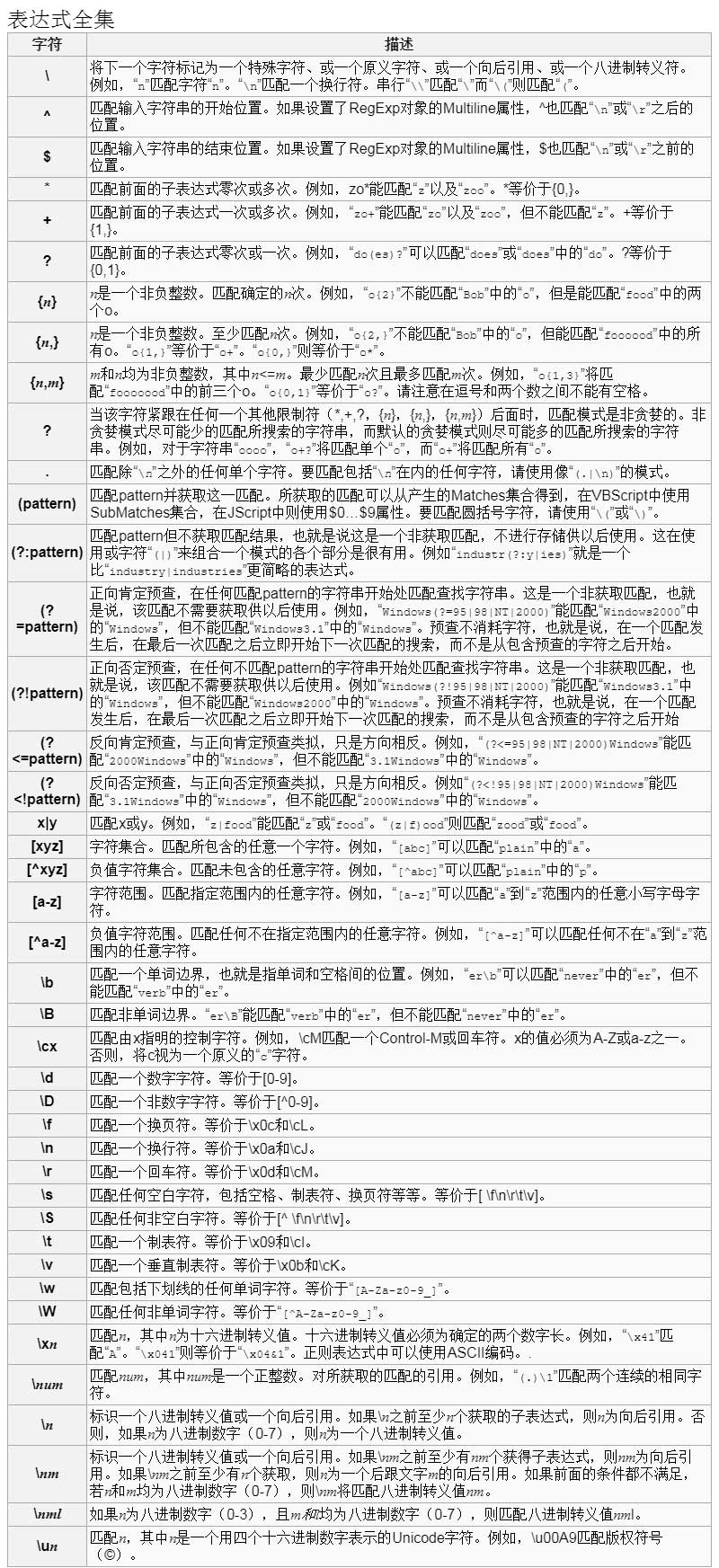
2.元字符
- 原义文本字符
代表它本来含义的字符。比如正则表达式/abc/、/123/,它们分别匹配的是abc、123 - 元字符
在正则表达式中,有特殊含义的非数字字符。如:\b\d\w.+()等。部分元字符的含义并不唯一,在不同的书写方式,含义可能不同。
元字符表,下图来自网址
3.工具推荐
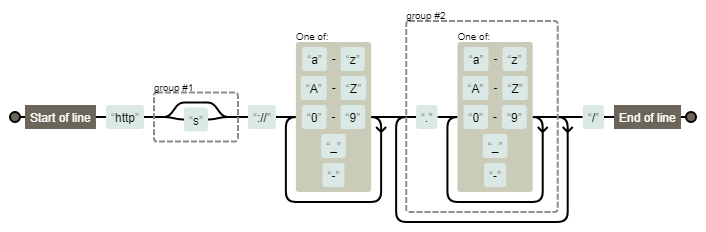
使用https://regexper.com 将正则表达式转换成状态机图。
例如将^http(|s):\/\/[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+\/$ 转换成如下图所示:
4.量词
| 字符 | 含义 |
|---|---|
| ? | 出现零次次或一次(最多出现一次) |
| + | 出现一次或多次(至少出现一次) |
| * | 出现零次或多次(任意次) |
| {n} | 出现n 次 |
| {n, m} | 出现n 到m 次 |
| {n,} | 至少出现n次 |
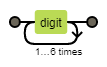
1 | // \d 表示匹配数字 |
使用https://regexper.com 图解\d{2,7}
5.贪婪模式和非贪婪模式
从上面4.量词 的例子中,'1234567890'.replace(/\d+/, 'a') 输出的是a 而不是a234567890;'1234567890'.replace(/\d{2,4}/, 'a') 输出的是a567890 而不是a34567890。
- 贪婪模式
正则表达式尽可能多的匹配,一直到匹配失败 - 非贪婪模式
正则表达式尽可能少的匹配,一旦匹配成功就不再匹配
默认情况下,正则表达式都是使用贪婪模式做匹配的。如果想要让正则表达式使用非贪婪模式匹配,在量词后面加个? 就可以了。
1 | '1234567890'.replace(/\d{2,4}/, 'a') // => a567890 |
6.类
- 正则表达式中,可以使用
[]来构建一个类,正则表达式中的类是指符合某些特性的对象
字符类
正则表达式[abcd] 是吧a、b、c、d 归为一类,该表达式可以匹配这类字符
1 | '12345a6b7c8D9e'.replace(/[abcd]/g, '|') // => 12345|6|7|8D9e |
范围类
正则表达式提供了[a-z] 来表示从a 到z 的任意字符(包含a 和z)
1 | '1a2b3c4T5Z'.replace(/[a-z]/g, '|') // => 1|2|3|4T5Z |
使用https://regexper.com 图解[a-zA-Z0-9]
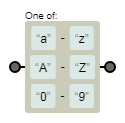
预定义类
| 字符 | 等价于 | 含义 |
|---|---|---|
| \d | [0-9] | 数字字符 |
| \D | [^0-9] | 非数字字符 |
| \w | [a-zA-Z0-9_] | 字母、数字、下划线(单词字符) |
| \W | [^a-zA-Z0-9_] | 非字母、数字、下划线(非单词字符) |
| \s | [\t\n\x0B\f\r] | 空白字符 |
| \S | [^\t\n\x0B\f\r] | 非空白字符 |
| . | [^\n\r] | 除了换行回车之外的任意字符 |
7.边界
| 字符 | 含义 |
|---|---|
| ^ | 以xxx 开头 |
| $ | 以xxx 结尾 |
| \b | 单词边界 |
| \B | 非单词边界 |
1 | 'img/png/img-1.png'.replace(/img/g, 'image') // => image/png/image-1.png |
8.分组
作用
- 与
|使用 - 与量词使用
- 反向引用
与| 使用
使用https://regexper.com 图解 /http(|s):\/\//
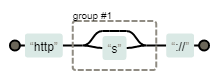
1 | /http(|s):\/\//.test('https://') // => true |
与量词使用
如何匹配java 出现两次javajava?
1 | /java{2}/.test('javajava') // => false |
反向引用
含有分组的正则表达式匹配成功时,将子表达式匹配到的内容,保存到内存中一个以数字编号的组里,可以简单的认为是对一个局部变量进行了赋值,这是就可以通过反向引用方式,应用这个局部变量的值。
很多情况下,我们可能需要将某种格式的字符串转换成另一种格式的字符串。例如:将06/02/2018 转换成2018-06-02;将Markdown 语法的超链接[github](https://github.com/) 转换成HTML 的超链接<a href="https://github.com/">github</a>
1 | '06/02/2018'.replace(/(\d{2})\/(\d{2})\/(\d{4})/, '$3-$1-$2') // => 2018-06-02 |
忽略分组
有时候我们在写正则表达式时会多次使用分组,但有一些分组是不需要反向引用的,比如正则表达式/http(|s):\/\// 中的分组,我们不需要进行反向引用,这是我们应该使用(?:)来忽略分组
不忽略分组
使用https://regexper.com 图解 /http(|s):\/\//
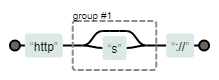
忽略分组
使用https://regexper.com 图解 /http(?:|s):\/\//
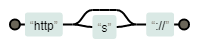
9.前瞻后顾
- 正则表达式从头部(左)向尾部(右)开始匹配的,文本的尾部方向称为“前”,文本的头部方向称为“后”
- 前瞻:正则表达式在匹配到规则的时候,向前检查是否符合断言
- 后顾:正则表达式在匹配到规则的时候,向后检查是否符合断言
| 名称 | 正则 | 含义 |
|---|---|---|
| 正向前瞻 | exp(?=assert) | 向前检查符合断言 |
| 负向前瞻 | exp(?!assert) | 向前检查不符合断言 |
| 正向后顾 | exp(?<=assert) | 向后检查符合断言 |
| 负向后顾 | exp(?<!assert) | 向后检查不符合断言 |
1 | 'ab2cde2fg'.replace(/[a-z](?=\d)/g,'X') // => aX2cdX2fg |
10.修饰符
global:是否全文搜索,默认是falseignoreCase:是否大小写敏感,默认是falsemultiline:是否多行搜索,默认是falselastIndex:是当前表达式匹配内容的最后一个字符的下一个位置source:正则表达式的文本字符
1 | 'aaaa'.replace(/a/,'A') // => Aaaa |
11.RegExp 对象中的test() 和exec()
test()
用于测试参数字符串中是否存在匹配正则表达式模式的字符串;如果存在则返回true,否则返回false
1 | const reg = /\w/ |
当时使用g 全文搜索时,test 函数会出现如下问题:
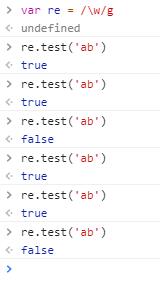
上述问题其实是正则表达式对象的lastIndex 属性在作怪
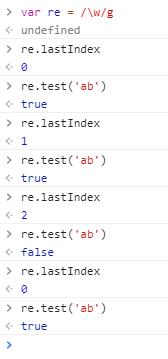
如果正则表达式使用了全文搜索g,又想避免上述问题,应在执行test 函数前先将lastIndex 置0
1 | const reg = /\w/g |
exec()
使用正则表达式对字符串执行搜索,并将匹配到的的结果以数组形式返回,如果没有匹配,返回null
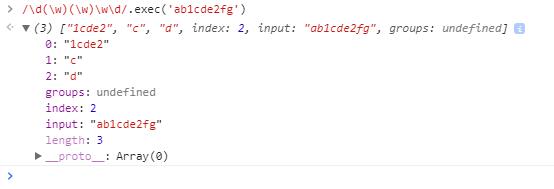
结果数组属性
index:匹配字符的第一个字符的位置input:被匹配的字符串
返回的数组
- 第一个元素是与正则表达式匹配的内容
- 第二个元素是与第一个子表达式相匹配的内容
- 第三个元素是与第二个子表达式相匹配的内容(以此类推)
现有如下字符串数组,我们使用exec 从每个元素中提取图片的路径
1 | const arr = [ |
正则表达式
1 | const reg = /\[.+\]\(http(|s):\/\/[a-zA-Z0-g_-]+(\.[a-zA-Z0-9_-]+)+\/((.+\/)+.+\.(png|jpg))\)/ |

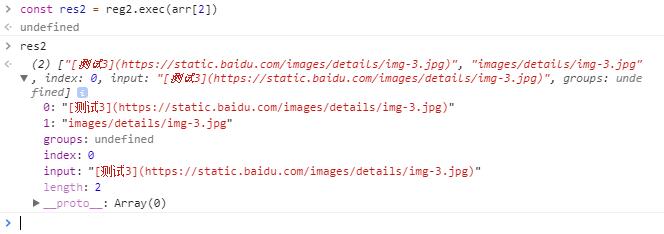
1 | const res = reg.exec(arr[2]) |
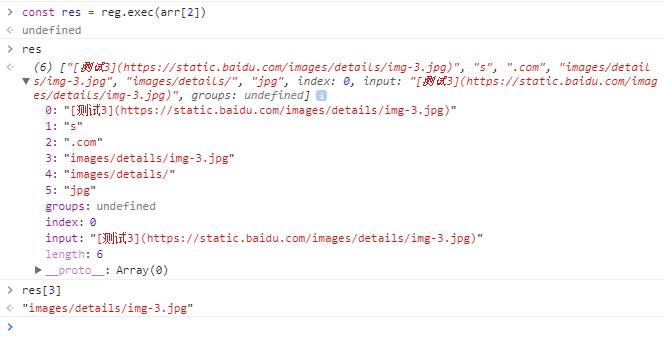
上述正则表达式使用了较多的分组,我们在阅读图形的时候可能造成干扰,可以忽略不必要的分组
1 | const reg2 = /\[.+\]\(http(?:|s):\/\/[a-zA-Z0-g_-]+(?:\.[a-zA-Z0-9_-]+)+\/((?:.+\/)+.+\.(?:png|jpg))\)/ |

1 | const res2 = reg2.exec(arr[2]) |